
Tesztesetek generálása AI-jal
2025-10-16
Egy korábbi projektünk kapcsán felmerült, hogy a hagyományos tesztelési módszereink mellett, azt támogatva, kipróbáljuk, hogy milyen ha a mesterséges intelligencia segít nekünk teszteseteket definiálni. Ezzel segítve a tesztelést végző kolléga dolgát. Most ennek, az ottani tapasztalataim alapján teljesen újragondolt menetét szeretném bemutatni.
A cikk bemutatja, hogyan lehet AI segítségével teszteseteket készíteni szoftverkövetelményekből. A folyamat magában foglalja a dokumentumok átalakítását, összefoglalását és a követelmények kigyűjtését.
Jelenleg Python-scriptekkel, lokális AI-val (ollama és gpt-oss:20b modell segítségével) dolgoztunk, de az elvek más AI modellekkel is működnek.
A módszer nem helyettesíti a szakértői felülvizsgálatot, de gyorsabbá teszi a tesztelés előkészítését és növeli a lefedettséget.
Folyamat terv
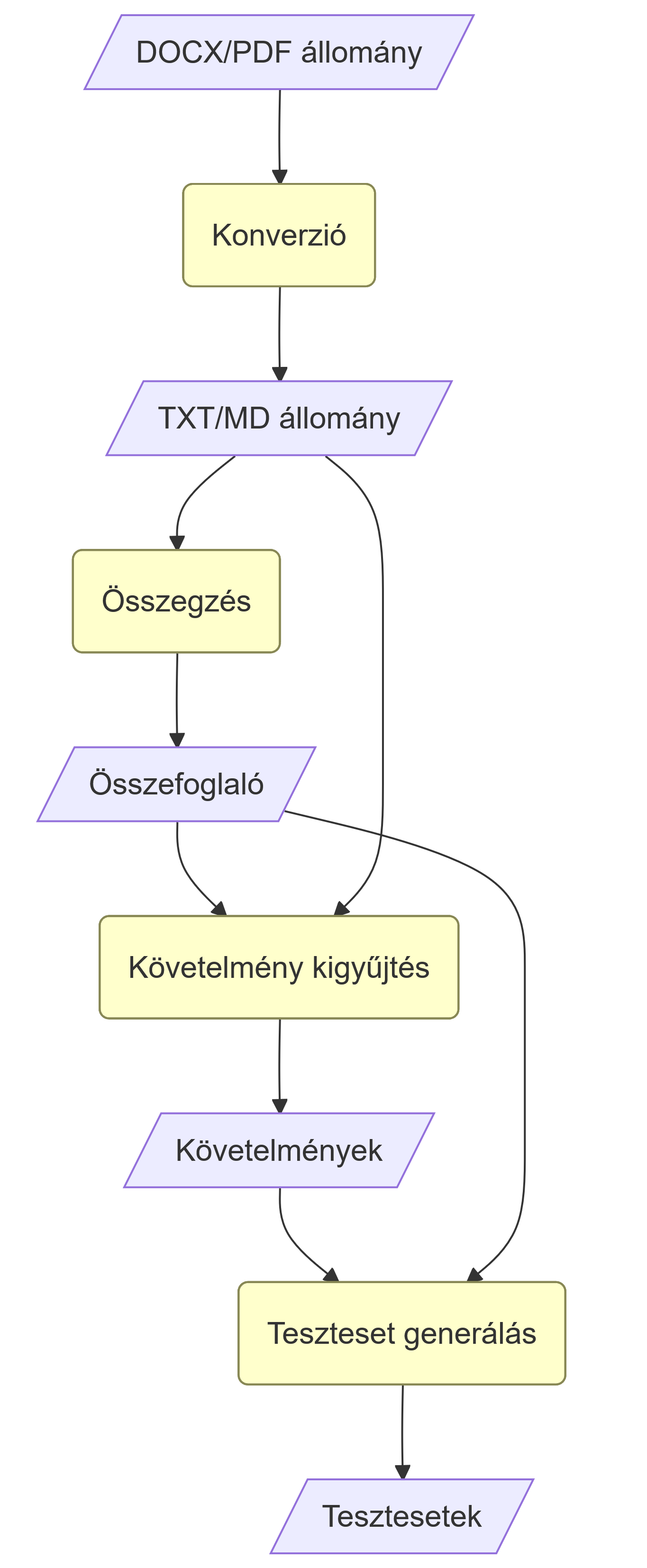
Kiindulási helyzet
Rendelkezünk egy követelménspecifikációval. Ez szabadszövegesen és/vagy pontokba szedve tartalmazza a követelményeket.
Jelen példához generáltattam egy minta követelményspecifikációt egy vállalati contact manager programhoz, ezt külön nem teszem elérhetővé, remélhetőleg látott már mindenki ilyet.
Konverzió - Szöveges állományok átalakítása
A gyakorlatban általános, hogy a kapott követelményjegyzékünk docx vagy pdf formátumban van. Ezeket a feldolgozáshoz át kell alakítani txt vagy markdown formátumba. Ehhez elég lehet a Wordben a Mentés másként funkció is, de léteznek olyan eszözök, amivel szépen és hatékonyan lehet ezt programozottan is megtenni:
Dokumentum összegzése
A kapott dokumentum alapján AI-jal gyártatunk egy tömörített 2-3 mondatos összefoglalót. Amennyiben hosszú a kiindulási dokumentum, úgy azt darabolni szükséges, és egy olyan prompttal célszerű megkérni az LLM-et az összefoglaló készítésére, ami az előző összefoglaló állapotot módosítja a következő dokumentumrész alapján.
Minta prompt:
You are assisting in summarizing a long IT document. The document is being processed in **chunks** due to model limitations.
Your task is to maintain and **refine a concise, high-level summary** of the system based on the current accumulated notes and the new chunk of the text.
### Input:
Current summary (accumulated so far):
```{SUMMARY}```
New Chunk of the document:
```{CHUNK}```
Update and reorganize the current summary using the new information.
Instructions:
- Rewrite the notes if necessary to ensure clarity, consistency, and logical structure.
- Merge or rephrase related items to avoid duplication.
- Make sure the notes read like a coherent, CEO level summary / pitch.
- Summary is maximum 2-3 sentence long high level description of the software system, one paragraph, wihtout deeper details.
### Output:
Return only the **refined and updated summary** as a single consolidated block, maximum 2-3 sentences. Do not include explanations or the chunk itself.A fenti minta specifikációból az alábbi összesítés készült el:
The Business Contact Management System is a centralized platform designed to help companies efficiently manage their business relationships by organizing contact information, logging interactions, and tracking tasks. This system supports various entities such as companies, persons, notes, and tasks, while ensuring fast performance, robust security, reliability, and an intuitive user interface.Erre az összesítésre azért van szükség, hogy amikor a következő fejezetben a követelményjegyzéket feldarabolva elemezzük, a promptba ezt is beletesszük, hogy az AI ismerje a big picture-t, a kontextust amiben dolgozik.
Követelmények struktúrált kigyűjtése
Hasonlóan, mint az összesítés, ez is a dokumentum részekre bontásával történik, viszont itt kisebb részekben gondolkodhatunk. Jó kérdés mindig, hogy milyen algoritmussal bonsunk szét szöveget részekre. Erre többféle megoldás van, ezekre most nem térek ki, akit érdekel egy magyar nyelvű cikk elérhető itt a témában. Jelen példában simán az első dupla soremelésnél vágtuk a szöveget, amennyiben a szövegrész hossza meghaladt egy bizonyos hosszt.
Erre a darabolásra két okból van szükség:
- egyrészt az LLM maximális kontextsumérete korlátoz (főleg lokális feldolgozásnál)
- másrészt ha túl nagy szöveget kap az LLM, képes kihagyni belőle részeket, mondhatnám, hogy nem koncentrál eléggé.
A promptban megkérjük az AI-t, hogy szíveskedjen kigyűjteni az adott részben található követelményeket a teljes dokumentum összegzését figyelembevéve, YAML formában. Megadhatjuk, hogy milyen attribútumokat rendeljen még az egyes követelményekhez (pl. entitás, témakör, követelmény típusa, stb.)
Minta prompt:
We have a high level summary of a software requirement specification (SRS) only for context:
```{SUMMARY}```
Your task is:
You are a requirements analyst. Your task is to extract only the explicit requirements from the provided chunk.
Instructions:
- Extract requirements exactly as stated in the chunk. Do not create or infer anything that is not written.
- If a sentence contains multiple requirements, break them down into **atomic requirements** (each requirement must express only one need, condition, or behavior).
- Do not merge or generalize requirements. Keep them as close to the source as possible.
- Output the results in YAML, in English.
Return the output in the following YAML format:
```yaml
- requirement_statement: this is the requirement itself written clarly and testably
category: Functional | Non-Functional | UI/UX | Performance | Security | etc.
priority: Must have | Should have | Could have | Won't have
source: original text the requirement extracted from
rationale: why this requirement exists (if applicable)
topic: Business or technical topic this applies to (e.g., "eCommerce", "Authentication")
entity: Specific entity (e.g., "Login form", "User profile", "Order", etc.)
Now, analyze the following chunk:
```{CHUNK}```Mi is ez a YAML formátum? Ez egy strukturált és egyszerű formátum, amit utána géppel könnyen feldolgozhatunk, de embernek is könnyen olvasható/írható. Az AI modellek is kifejezetten jól kezelik.
Az eredmény így egy tömb, ami a követelményeket tartalmazza kicsit átfogalmazva és struktúrálva. Minden követelményhez hozzárendelünk utólag, programozottan egy egyedi azonosítót is, hogy a későbbiekben hivatkozni tudjunk rá.
Minta eredmény:
- category: Functional
entity: Company
id: REQ_018
priority: Must have
rationale: Allows entry of new company information into the system.
requirement_statement: Users must be able to create company records.
source: Users must be able to create, view, edit, and delete company records.
topic: Company Management
- category: Functional
entity: Company
id: REQ_019
priority: Must have
rationale: Provides visibility into stored company data.
requirement_statement: Users must be able to view company records.
source: Users must be able to create, view, edit, and delete company records.
topic: Company ManagementTesztesetek generálása
A sztori a már szokásos: a kigyűjtött követelményekhez egyenként felkérjük az AI-t hogy generáljon teszteseteket, hasonlóan YAML formátumban.
Minta prompt:
We have a high-level summary of the software for context:
```{SUMMARY}```
Your task is:
You are a QA assistant. Based on the following software requirement, generate a list of test cases.
Each test case must include a **title**, **description**, **type**, **subtype**, **domain**, **entity** and **req_id**.
Include both positive and negative test cases. Consider logical conditions, boundary cases, invalid inputs, and potential misuse or abuse.
Do not generate test cases for fields, attributes, behaviour or data not mentioned in the requirement. Focus strictly on what can be logically inferred from the given requirement.
Do not invent business-specific values or other attributes that are not specified.
Test cases should reflect: Correct system behavior, Graceful handling of invalid or unexpected input, Edge cases.
Use your domain knowledge to infer what aspects of the requirement need verification, even if not explicitly stated.
Return the output in the following YAML format:
```yaml
- title: Test case title
description: Description of the test case
type: Functional | Non-Functional | Boundary | Error Handling | Security | Usability | Performance | etc.
subtype: Positive | Negative | Edge Case | etc.
domain: Business or technical domain this applies to (e.g., "eCommerce", "Authentication")
entity: Specific entity under test (e.g., "Login form", "User profile", "Order", etc.)
req_id: The given requirement id, e.g. REQ_0001
- title: ...
description: ...
type: ...
subtype: ...
domain: ...
entity: ...
req_id: ...```
Requirement to generate test cases for:
```req_id: {id}
Category: {category}
Entity: {entity}
Statement: {requirement_statement}
Topic: {topic}
Rationale: {rationale}```Minta eredmény:
- title: Attempt to create company with disallowed special characters
description: Provide a company name containing special characters that are not allowed by business rules and verify that the system rejects the input with an appropriate error.
type: Functional
subtype: Negative
domain: Business
entity: Company
req_id: REQ_018
- title: Verify newly created company appears in the list
description: After successfully creating a company, verify that it appears in the company management list view and that its displayed details match the entered data.
type: Functional
subtype: Positive
domain: Business
entity: Company
req_id: REQ_018
- title: View Company Record with Valid Identifier
description: |
Verify that a user can successfully open and view the details of an existing company record
when they provide a valid company identifier from the system.
type: Functional
subtype: Positive
domain: Business
entity: Company record
req_id: REQ_019
- title: Attempt to View Company Record with Non‑Existent Identifier
description: |
Attempt to open a company record using an identifier that does not correspond to any record
in the database. Confirm that the system displays an appropriate error or not‑found message
and does not expose internal data.
type: Functional
subtype: Negative
domain: Business
entity: Company record
req_id: REQ_019Az eredményt már könnyen lehet excelbe exportálni, és teszteléshez használni.
Tapasztalt nehézségek
- Kontextusvesztés: A fenti módszerrel mindig csak egy-egy részét látja az AI a specifikációnak, követelményeknek, ezért nem lesz mindig konzisztens a szóhasználat vagy a tudása, illetve duplikált tesztesetek jöhetnek létre.
- Túlzott kreativitás: Sok esetben az AI jót akar nekünk, és olyan követelményt vagy tesztesetet generál, ami nem következik szigorúan véve az eredeti dokumentációból. Megfelelő promptolással vagy LLM judge segítségével az ilyen eredmények kiszűrhetőek
- Formátum problémák: Az esetek nagy részében sikerül a YAML formátum tartása, de sokszor vét, főleg a karakterek escapingjében. Ez bosszantó dolog, de erre is létezik megoldás
- Nyelvi kihívások: Ha esetleg magyar nyelvű az input dokumentum, lehetnek problémák a megfelelő értelmezéssel és szóhasználattal.
Összegzés
A bemutatott folyamat célja, hogy a mesterséges intelligenciát (LLM-eket) bevonjuk a tesztesetek előállításába – nem a hagyományos tesztelés kiváltására, hanem annak támogatására. Gyorsan, átlátható szerkezetben képes nagy mennyiségű és strukturált teszteset-javaslatot előállítani a követelmények alapján. Ez különösen hasznos amikor még a tesztelés előkészítése zajlik.
Az AI által generált tesztesetek nem helyettesítik a szakmai felülvizsgálatot, de jelentősen csökkenthetik az előkészítési időt és segíthetnek a lefedettség növelésében.
Ugyanakkor érdemes figyelembe venni néhány korlátot is:
- A modell a bemeneti szöveg minőségétől és részletességétől függően teljesít jól.
- A teszteseteket mindenképp szakértői review után érdemes véglegesíteni.
- A módszer nem váltja ki a domain-specifikus tudást vagy az üzleti logika mély megértését.
Az AI-alapú teszteset-generálás különösen azokban a szervezetekben hasznos, ahol a követelmények jól dokumentáltak, a tesztelés rendszeres, és nyitottság van az automatizálásra. Összességében nem csodaszer, hanem egy hatékony új eszköz, amellyel megfelelő használat mellett idő, energia és költség takarítható meg.