
AI támogatott fejlesztés lokális modellekkel
2025-10-07
Korábban Tabnine-t, majd Windsurföt (régi nevén Codeium) használtam AI támogatott fejlesztéshez. De miről is van szó pontosan?
Többek között:
- Kódkiegészítés – miközben írom a forráskódot, az AI kitalálja, hogyan folytassam, és megírja a hátralévő kódrészt a legjobb tudása szerint;
- Chat parancs alapú fejlesztés – kijelölök egy kódrészt, majd egy chatablakban megadom, milyen módosításokat szeretnék, és az AI elvégzi a változtatásokat;
- Kontextusfüggő chat – az AI chatbot ismeri a kódbázist, így válaszol kérdéseinkre és tervezési tippeket ad.
Nemrég programozás közben leütöttem néhány billentyűt, vártam, hogy az AI megírja az utolsó öt sort… de nem érkezett válasz. Ekkor vettem észre, hogy elment a net. Kénytelen voltam fejből fejleszteni. Ez az élmény ráébresztett, hogy túlságosan támaszkodom az AI támogatásra. Ez is hozzájárult ahhoz, hogy lokális AI megoldás után kezdjek kutatni.
Miért jó a lokális eszköz?
- Offline működés - az előző példám is mutatja, internet nélkül is használható;
- Tetszőleges AI modell használata - teljes szabadság;
- Adatbiztonság - a forráskód indexelése és feldolgozása teljes egészében lokálisan történik, harmadik félhez nem jut el;
- Függetlenség - aki ismer, tudja, hogy sok mindent “self-hostolok”, és ez itt sincs másképp.
Környezet kialakítása
Hardverkövetelmények
A lokális működést egy kedves ismerősöm által kidobásra ítélt Nvidia GTX 1060-tal kezdtem kipróbálni. Működött, bár választhattam, hogy lassú vagy korlátozott intelligenciájú legyen a rendszer. Ez megerősített abban, hogy érdemes fejleszteni, így beruháztam egy RTX 5060 Ti-re, 16 GB memóriával. Ez a belépő szintnél egy lépéssel jobb megoldás volt, és akciósan jutottam hozzá. Ezen már a nemrég megjelent OpenAI gpt-oss:20b modell remekül fut.
Megjegyzés: korábban sosem vásároltam gamer jellegű videokártyát, ez az első ilyen alkalom. Azóta még játékot sem indítottam rajta.
Ollama
Aki lokális AI-val szeretne ismerkedni, érdemes telepíteni az Ollama programot. Windows alatt ez egy egyszerű “next, next, finish” folyamat. Innentől kezdve könnyedén indíthatunk lokális chateket parancssorból:
$ ollama run qwen3:0.6bAz Ollama letölti a modellt a gépre, betölti a videomemóriába, majd futtatja.
Megtekinthetjük az elérhető modelleket és a memóriahasználatot:
$ ollama ls
$ ollama psAjánlott általános modellek ehhez a videokártyához:
- gpt-oss:20b
- qwen3:14b
- gemma3:12b
Speciális “coder” modellek, amelyek fejlesztéshez ideálisak:
- qwen3-coder:30b
- qwen2.5-coder:14b
Könnyen válthatok a modellek között, és az Ollama kezeli a betöltést, háttérben fut a gépeden. Emellett van hozzá modell tár is az ollama.com-on.
llama.cpp
Az Ollamának vannak korlátai: alapértelmezésben kis kontextusablakkal dolgozik, ami kódkiegészítésnél problémát okozhat. Ezzel szemben a llama.cpp egy másik világ: manuális unzipelős telepítés, parancssori paraméterek tucatjai, és webes chatfelület.
Például így indítok egy gpt-oss:20b modellt:
$ llama-server -hf unsloth/gpt-oss-20b-GGUF:F16
--jinja -ngl 99 --threads -1 --ctx-size 16384
--temp 1.0 --top-p 1.0 --top-k 0 --port 8888És így egy qwen2.5-coder:14b modellt:
$ llama-server -hf Qwen/Qwen2.5-Coder-14B-Instruct-GGUF:Q5_K_M
--port 8888 -c 16384A futó modellhez webes felület tartozik, amely hasonlít a ChatGPT-re: http://localhost:8888/
Tabby
Ha fut a modell, jó lenne integrálni a fejlesztőeszközbe kódkiegészítéshez és chateléshez. Itt jön képbe a Tabby.
Windows alatt az unzipelős verziót telepítettem, majd konfiguráltam a ~/.tabby/config.toml fájlban, hogy a llama.cpp által futtatott “backend” legyen használatban:
[model.completion.http]
kind = "llama.cpp/completion"
api_endpoint = "http://localhost:8888"
prompt_template = "<|fim_prefix|>{prefix}<|fim_suffix|>{suffix}<|fim_middle|>"
[model.chat.http]
kind = "openai/chat"
model_name = "chat-model"
api_endpoint = "http://localhost:8888"
[model.embedding.local]
model_id = "Nomic-Embed-Text"Indítás:
$ tabby.exe serve --port 10081Ez egy felületet ad statisztikákkal, chatelőzményekkel, és lehetőséget ad Git repository indexelésére (Context Providers menü). Ezután telepíthetjük a Tabby plugint a VS Code-ba vagy IntelliJ IDEA-ba, és összekapcsolhatjuk a Tabby szerverrel. Innentől IDE-ből tudunk chatelni és kódkiegészíteni.

A fenti videokártyával a qwen2.5-coder:14b modellt ajánlom: gyors és megbízható.
Aider
Érdekességként említeném az Aider eszközt, ami egy parancssoros pair programming agent. Elindítva egy repóban parancsokat adhatunk neki kódírásra vagy módosításra. Miután végez, még commitol is.
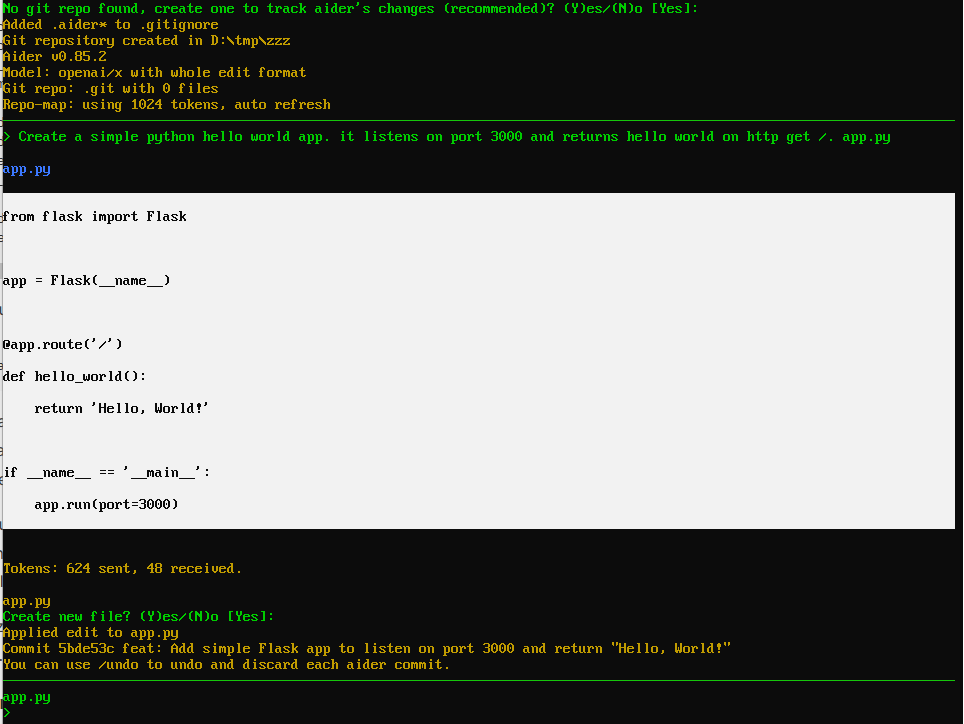
A fenti konfigurációval a gpt-oss:20b modell jól működik: gyors, bár nem tökéletes, de használható.
Kiértékelés
A Windsurf helyett lokális megoldást kerestem. A Tabby és az Aider két nagyszerű eszköz saját hostolt AI modellekhez. Ezek közelítik a Windsurf szintjét, bár vannak hibák és glitch-ek, amelyeket remélhetőleg idővel javítanak.
Egyes új technológiáknál (például Svelte 5) a modellek lemaradnak, így továbbra is függünk a frissítésektől. Szomorú tény, hogy szinte minden open-source és self-hosted megoldásnál felkerül a weboldalkra a pricing menüpont, és sok esetben startup módjára pivotolnak. (Korábban a Continue plugint próbáltam lokális modellekkel, de ott is változtak a dolgok, rájöttek, hogy inkább külön IDE-t fejlesztenek, mint plugint - kár érte.)
Majd írok a hosszútávú tapasztalatokról is. A következő bejegyzésben várhatóan teszteseteket generálunk funkcionális specifikáció alapján, szintén lokális modellel.